


LLMs Reliability - learnings from the CTO of Persana.ai


More than a decade ago, when I studied echo state neural networks, AI was mainly in Academia and the main tool I had was Matlab. When I got a job at SAP, it was chatbots and orchestration engines, and now it’s Agents. While tempting to believe it’s the same thing with a new name, agents actually have something new, and it’s not just branding. What has changed is how good they have become. We’ve seen chatbots back in the day, and they did automate a bunch of work but now the immense productivity of these agents is unprecedented. They can do a lot of tasks a human would spend a lot of time on. Before, it was more rules-based, but now it can do a lot of steps and reasoning, and this year the output we get from AI has gotten even better. Now we think of Agents as an AI teammate. They go beyond one single workflow and automate an End-to-End business operation.
While the benefits are clear for agents, it’s not as clear how to obtain them. 80% of AI apps that are built for enterprise use cases fail and are not pushed to production, according to Harvard Review. How can you be in the 20% that make it? Ship AI that’s reliable. Earn your users’ trust.
Highlights
Build trust through pragmatic AI automation. It's crucial to recognize that success lies in embracing intermediate capabilities rather than chasing full autonomy. A good framework of what could be automated vs. not is customers' tolerance level on error rates. What’s the cost of the error
Reduce the hallucinations. The accuracy of the models is improving, but hallucinations will still be an issue. We need to ensure that the AI Agent is not hallucinating (fabricating inaccurate information) since, now that they can take action, they could do something very harmful.
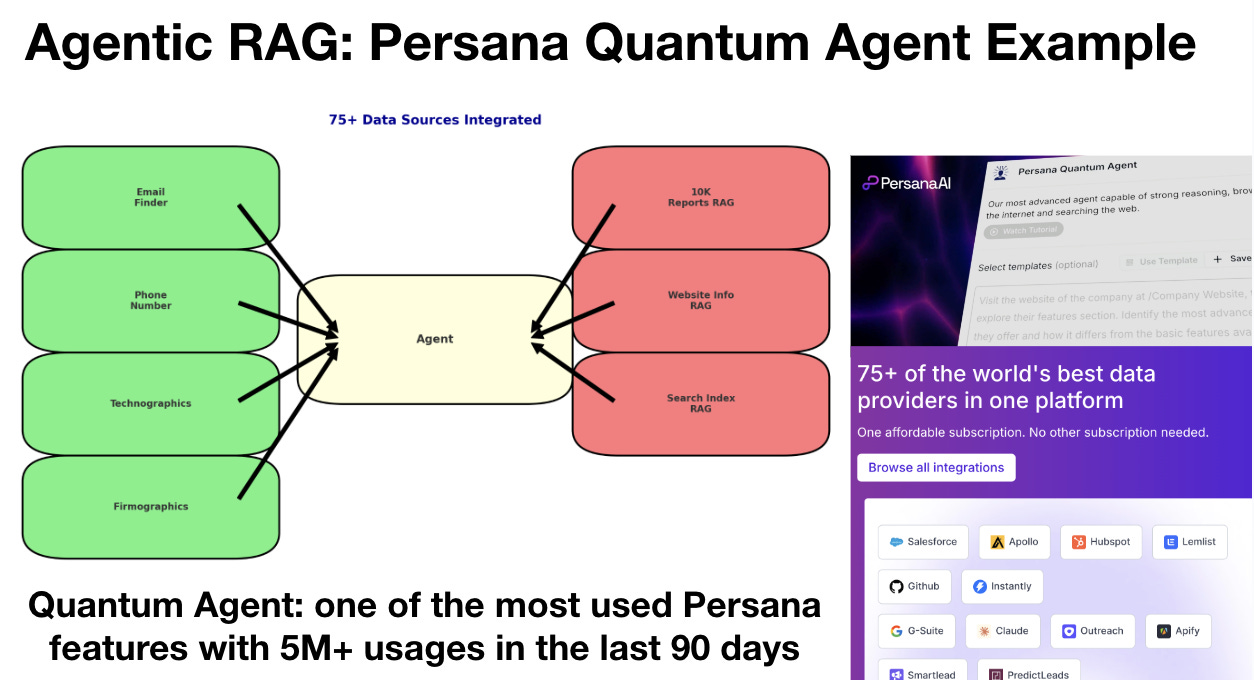
Implement Agentic RAG. All companies must try to give users the ability to do tasks on their behalf all in one interface. An example of Agents plus RAG, is Persana Quantum Agent which reached 5m+ usage in the last 90 days. Customers love it.
Debias the data. Benchmark datasets for bias testing, make sure the agent is not saying anything harmful, and send the output back to an LLM to ask if it said anything harmful. However, also check the input thoroughly (in case user content contains harmful or biased content) before you feed it into an LLM.
Use tools. There are many tools mentioned to increase reliability. Some mentioned in this article that we recommend you check out are: LangGraph, Wordware, LlamaIndex, Okareo, Galileo, Arize, RAGAS, SuperAnnotate, Pinecone, and Helicone.
I will use examples from a YC Startup, Persana.ai that is building GTM AI Agents. I am not an investor. This is not a promotional blogpost. If your tools can provide value to AI builders, comment or DM, and I will include them, similarly, if you have any learnings to share on how you do LLM Reliability, please share, and I will include them. The CTO of Persana was the guest speaker of the ACM(Association for Computing Machinery) tech talk I moderated, and he also authored a book on LLM Reliability.
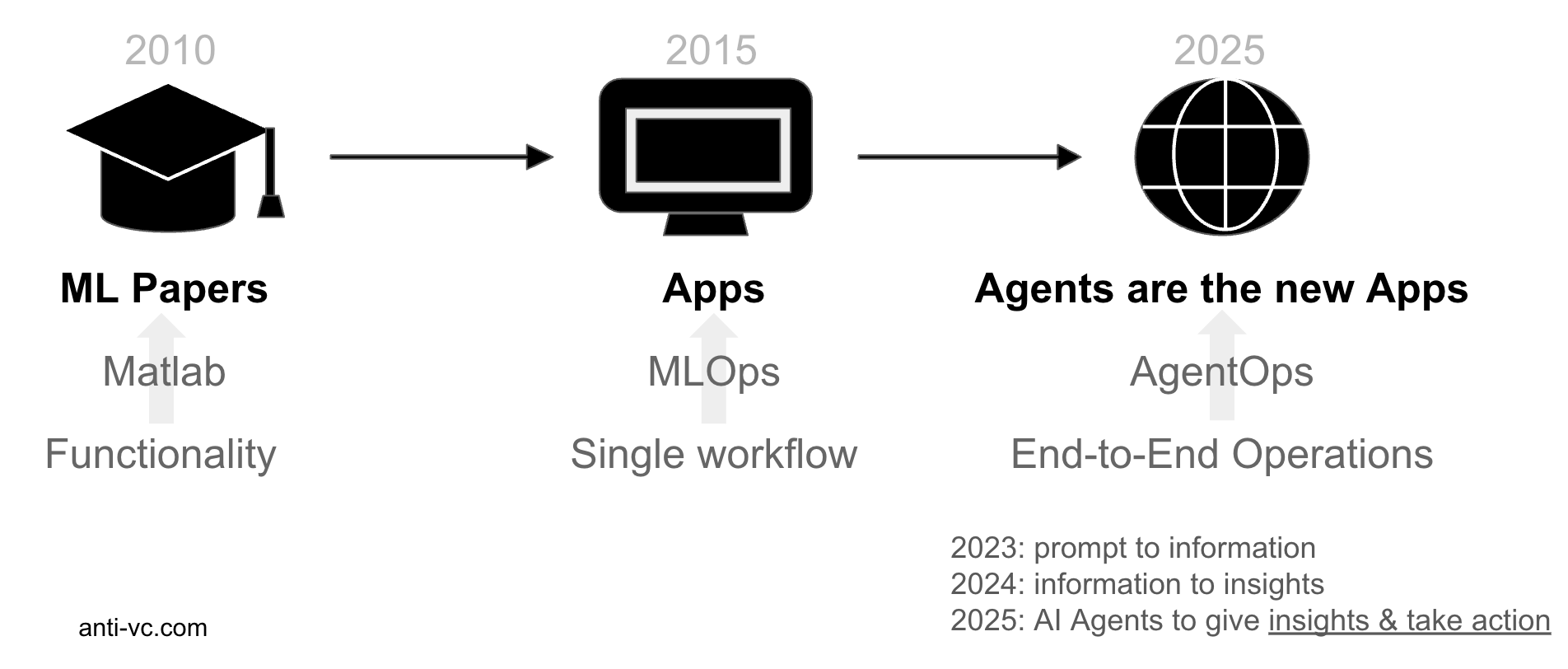
Building Trust Through Pragmatic AI Automation
We don’t have full Agentic AI today, the “ you can take your mind off” kind. It could take a decade to address long-tail failures, highlighting the necessity of realistic expectations and incremental advancements. There are no magic shortcuts. Today we have “hands off” AI, and this can generate a lot of business value. When deciding what to automate with AI, it's essential to take a pragmatic approach rather than chasing the dream of full autonomy. The key is to evaluate each task through the lens of risk and impact: can your customers tolerate occasional mistakes, and what would those mistakes cost? In customer support, for instance, having an AI help agents find relevant information is low-risk and high reward, while letting AI make final decisions about refunds or account closures could be costly. This is why personal injury law firms are successfully using AI to help draft demand packages - the AI assists lawyers rather than replacing them, and all output is reviewed by professionals who can catch and correct any errors. You can read more about it here.
Reduce the hallucinations
We need to make sure the AI Agent is not hallucinating (fabricating inaccurate information) since now that they can take action, they could do something very harmful. Causes for hallucinations are training data limitation, lack of real-time retrieval, and overconfidence in uncertain responses. How to reduce it:
Choose a better foundation model (e.g. GPT4 has less hallucinations that GPT3.5)
Tune model parameters
Use prompting techniques
Fine-tune your model
RAG (Retrieval Augmented Generation)
Agents and Tools
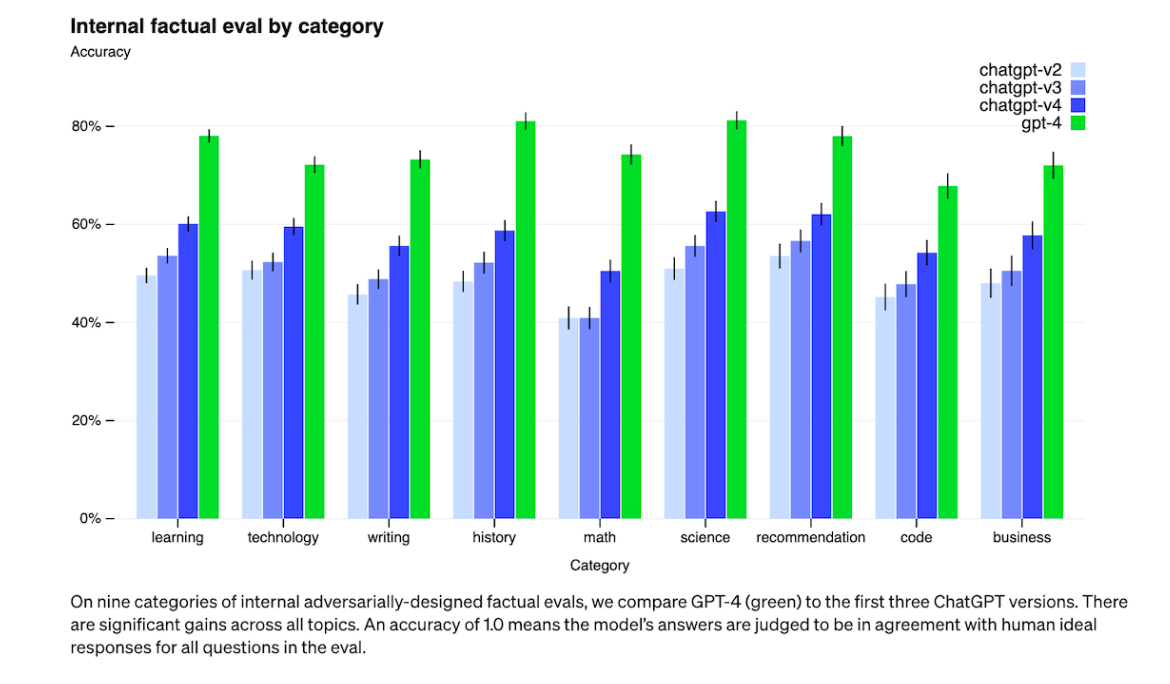
Chart: showing how models are improving over time
Takeaway: as the models are getting better and better, the accuracy is getting better, but hallucination is still going to be an issue
Reducing hallucinations with prompting
Use assertive voice (ALL CAPS), put rules at the start, be descriptive, use examples, add context in the prompt, and ask the model to act like an expert in your field as the model to substantiate claims (citations).
Tree of thought prompting
Instead of figuring out one path, it figures out all paths that could happen. For example, if you’re trying to solve a sudoku puzzle, you don’t know what the end board is, but if you try one number and then try the next number, and then you try the next number, you’ll eventually find the right path. You can get the LLM to build a tree for you which is going by each step. Another enterprise use case example is a customer telling a chatbot that his TV is malfunctioning. The LLM can evaluate three options:
1) Return it if it’s in the 30-day window
2) Manufacturer 1 year warranty if it is outside of 30-day
3) Replace it with a new one if it’s within 90 days of purchase
The ACM tech talk guest speaker said his favorite way to evaluate LLMs at the startup he’s building, Persana.ai is by calling another GPT or another LLM to check if the answer is helpful. You can also ask it to evaluate bias.
You can try to see what techniques work best for you - offer your model a tip? Source.

RAG (Retrieval Augmented Generation)
RAG combines large language models (LLMs) with real-time information retrieval. It will dynamically fetch context from external sources like your database. You have to make sure your knowledge is up to date-and grounded (from specific documents and sources). Tells the LLM to only answer the users’ question from the given data. If the question cannot be reliably answered, the model should state that it cannot answer the question.
Step by step
Extract and Split data into Chunks. Tools: Langchain, CharacterTextSplitter
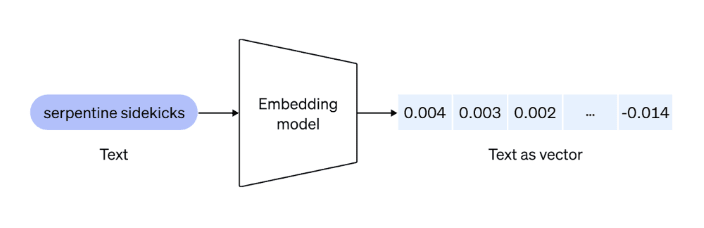
Create embeddings of each of the chunks (You can use OpenAI Embeddings Ada). Embeddings capture the meaning/semantics of the text
Store the embeddings in a vector DB (eg. Pinecone)
Retrieval
User enters their query
We run an embedding search to find the most similar embeddings to the query
Ask the LLM to answer the users query based on the documents we found in step b
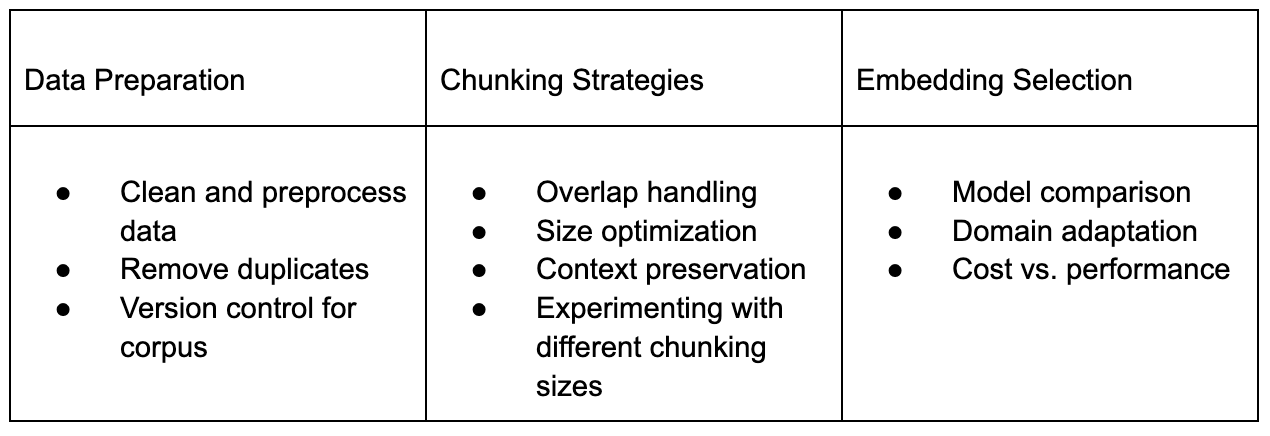
RAG Best Practices
Example at Persana.ai: they keep 10-20% overlap in chunks to capture context where it is in the document. They were scraping websites and using RAG and realized links were not working, and the reason why it was giving incorrect links was that links in websites don’t include the full URL. They might include part of the link, and the rest is in HTML so including that context in the chunk, making it slightly larger helped.
The accuracy takes a huge dip in the middle. While some models support longer token limits (e.g., GPT-4's 32k tokens), the effectiveness of retrieval for context-based accuracy and RAG can decline significantly beyond approximately 2000 tokens due to model attention limitations. To mitigate this, use effective chunking strategies and semantic search to select the most relevant chunks or consider splitting prompts to better handle larger contexts.
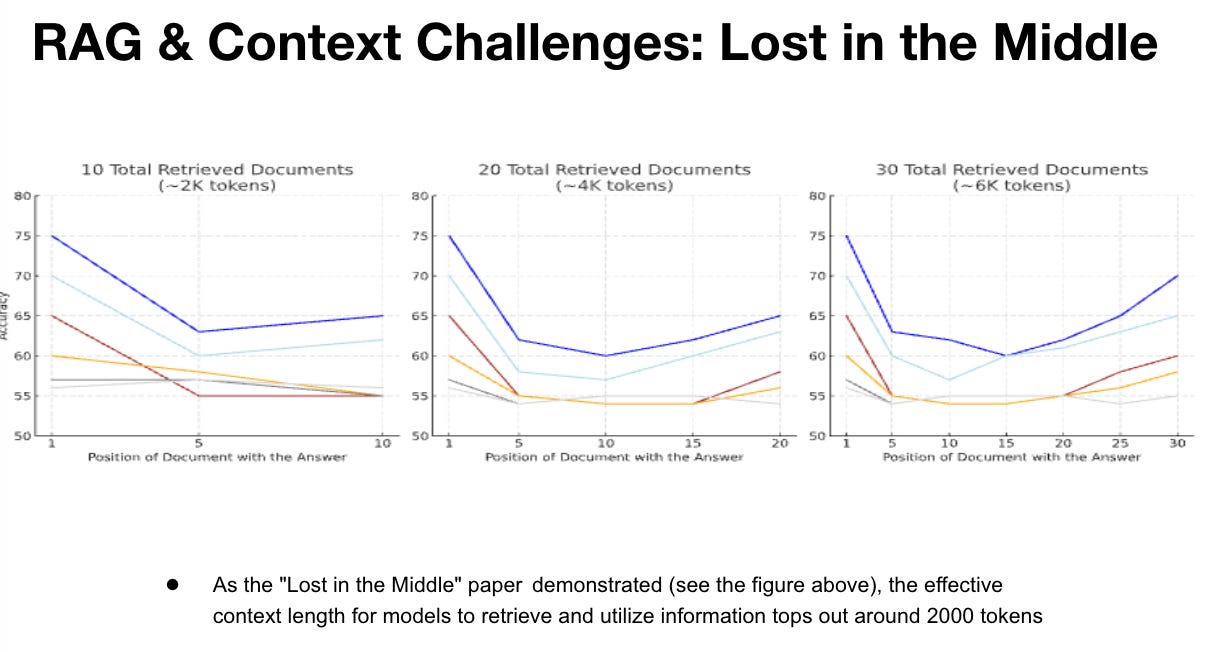
How to reduce hallucinations:
Make sure the data is verified and up to date. Retrieval of verified data ensures factual accuracy.Example:
Query: "What are global temperature trends?"
Without RAG: "Outdated Data”
With RAG: "Global temperatures rise ~0.18°C per decade (source: IPCC)."
Metadata Filtering & Advanced RAG Techniques
Reducing Noise: Use semantic similarity filters to focus on relevant data.
Metadata Filtering: Leverage document tags to refine retrieval.
Hybrid Search: Combine RAG with Keyword Based Search.
Keeping domain data up to date in RAG systems requires a combination of strategies to ensure accuracy and relevance. One effective method is to implement version control, maintaining multiple versions of datasets with metadata like version numbers or timestamps, allowing for systematic updates. Delta updates can also be employed to identify and modify only the affected chunks rather than rebuilding the entire vector database, saving time and resources. Automated data ingestion pipelines can streamline this process by fetching, preprocessing, and indexing new data as it becomes available, using tools for orchestration. Additionally, hybrid search techniques can combine vector search with metadata or keyword-based retrieval to prioritize more recent information when embeddings are slightly outdated. Modular storage of embeddings, separating static foundational knowledge from frequently updated dynamic data, further simplifies updates. For data that relies on third-party sources, effective tooling should be set up to auto-update indexes, ensuring timely integration of changes. Together, these strategies create a robust system for maintaining up-to-date and reliable domain data in RAG workflows.
Implement Agentic RAG
Agents are the new apps
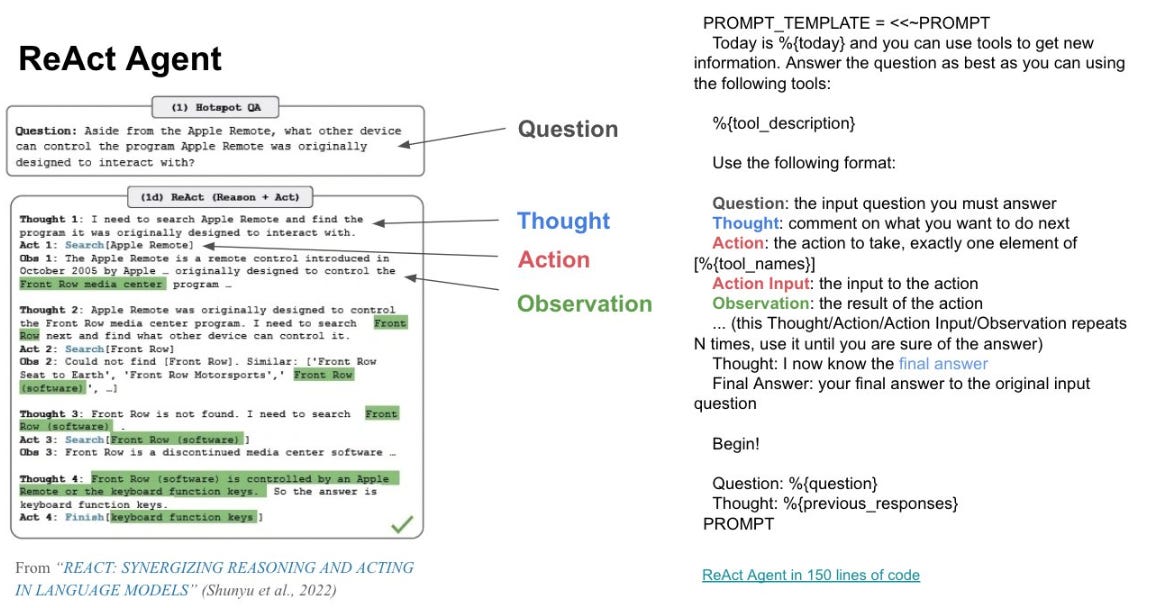
Last year was all about copilots, and now it’s agents. All companies try to give users the ability to do tasks on their behalf all in one interface. Agents are different from RAG because they can access tools: API, database, new application etc. One of the main frameworks is the ReAct Agent.
Example from Persana’s 5m+ usage in last 90 days: Persana Quantum Agent.
Agentic RAG is RAG plus Agents, and an agent has access to both RAG sources and tools.
Instead of buying a subscription to each of the different tools, you can integrate your own or use the Persana marketplace and the DB. If you search for a phone number, it should go to the phone number source, not the website.
How to monitor RAG and agents
Create a test data set, and with every interaction, ensure your RAG pipeline platform answers them effectively. You can monitor RAG in production with tools like Okareo and Galileo. A free tool is the RAGAS Evaluation Metrics for RAG and Agents (Python package).
For agents, it’s not just the output but also how it does it. It has three parts: the router, the execution path, and the performance. Be really descriptive in your function description, write good prompts, and make sure you’ve given your agent all the tools that it needs to answer the question.
Comprehensive Agent Evaluation:
- Beyond just skills: evaluating the complete agent pipeline
- Key areas: Router, Execution Path, and Performance
- Critical for reliable agent systems
Tools: Arize AI, Galieo, Okareo.
One has to evaluate the agent also for bias and ethics as their neglect can lead to erosion of trust as well as legal and reputation risk. One needs a diverse and inclusive training data set. As well as regular audits for bias detection. One can incorporate fairness metrics too (e.g. demographic parity). AI systems are only as fair as the data they're trained on.
LLM Challenges: Hallucinations and bias undermine trust and reliability.
Mitigation Techniques: Effective prompting, RAG, and self-checking models reduce risks.
AI Agents: Autonomous agents are the future—when grounded and monitored properly.
Ethics First: Prioritize fairness, inclusivity, and transparency in AI design.
Continuous Evaluation: Regular monitoring & evaluations are essential for scalable, reliable AI systems.
Use tools
LangGraph is really good for multi-step. LlamIndex is great for building simple RAG, and Wordware for quickly building agents on a web IDE.
The RAGAS framework is helpful in estimating hallucinations. Having a human is still useful but if you don’t have it, ask another LLM as a judge as a really easy way. Before sending it to the user, we ask another LLM, have we answered the user's question? Have we said anything harmful?
Cost. Even bigger companies find it expensive to use GPT4 for evaluation, so they send it to a cheaper model for evaluation. Most of the people don’t use the best models to run the evaluations. Experiment and see which models work best for your use case.
Agentic RAG. LangSmith for tracing. Okareo and Arize are also good, but there are tons. Also Helicone to keep track of the LLM calls you’re making. A lot of observability tools are coming out.
I hope you learned something from this blog post. My parting thoughts are to give users visibility into where the data comes from and what steps the model took to give them the answer. So the customer can see if this quality data is what they want. Also, they can tune it to select only data sources from where the model gives them an answer. Trust is earned, and it’s built at every step of the agent development lifecycle.
If you have additions to this post and/or want to talk about LLMs and agents, please DM.
Thanks to ACM and Rush for reading drafts of this.