


Fine Tuning LLMs - learnings from the DeepLearning SF Meetup

11 years ago, NASA marked the 135th and final mission of the American Space Shuttle program. I was in the rainy north of Germany, in undergrad, researching echo state neural networks for handwritten recognition; you can read my thesis if you want to see how far the field has come. I used Matlab, it was painful and definitely not considered cool. Fast forward, and you can’t throw a stone without hitting someone speaking about large language models (LLMs) today. And yet, most resume at speaking instead of reaping the benefits in real life.
LLMs are generic and in order to make them useful to your particular domain, they must be specialized. Besides the knowledge required to specialize these LLMs, there is also compute cost. While there is no magic button to push and 10x physical hardware, there are ways to lower the cost using software. I am personally optimistic that we will get to affordability. It costs like $10 to get human level vision model now, it used to cost >$100k. In this article I’m summarizing, in plain english, different methods for fine-tuning, and highlighting one method that is cheaper and elegant-LoRA.
My aspiration for this blog is that both people with entry level knowledge of AI take something away from it but also people who have used or played with a LLM.
Highlights
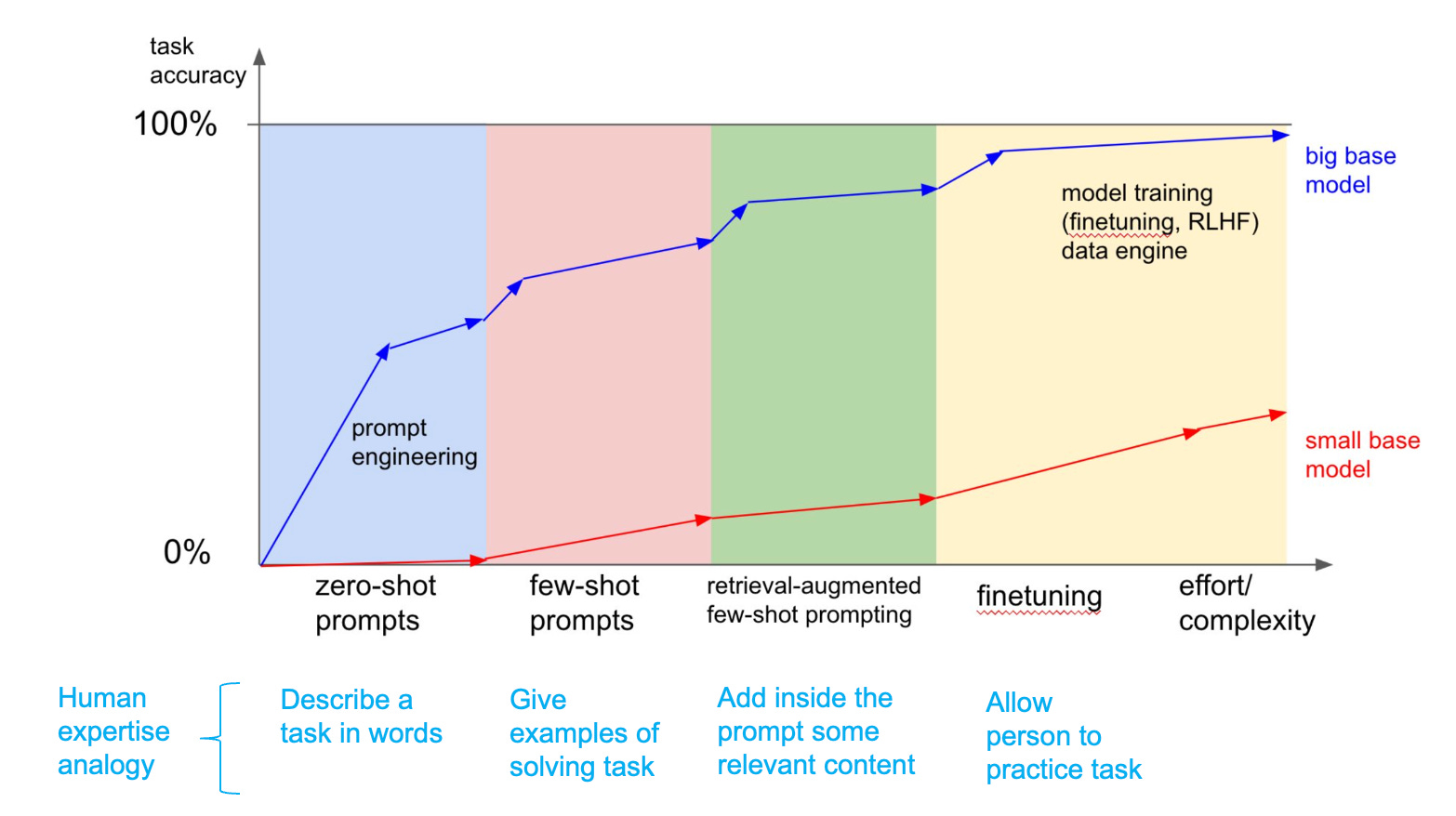
For big models you can get a pretty good start without fine tuning, just using prompt engineering. It’s expected you have to fine tune though, to reach top tier performance, especially in applications with concrete well-defined tasks where it is possible to collect a lot of data. For small models you get more wins from fine-tuning, zero and few shot don’t work as well.
It is becoming a lot more accessible to fine tune LLMs. With LoRA you get efficient training and serving performance and similar results as fine tuning end to end.
There is evidence that fine tuning helps with new task behavior. See a fine-tuned LLaMA model that significantly outperforms GPT-4 on a range of arithmetic tasks - GOAT.
Just extracting data out of the model naively(Alpaca) seems to just copy style but if you spend a lot more effort you can actually get quality improvement not just style - ORCA.
Direct preference optimization from Stanford emerges as an alternative to reinforcement learning with humans in the loop. Reinforcement learning is brittle, you need hyperparameter tuning and it’s hard to get it working.
Specializing LLMs - Fine-tuning vs prompt engineering
People want to use LLMs but for things they care about and are applicable to what they do. Think about it like giving the LLM a job, to work for you, it has to have expertise in your particular line of work, it has to specialize to get the job, similar to expertise in people. Here are three types of specialization you’ve probably heard about, but in plain english using the analogy of expertise in humans (source:karpathy):
Describe a task in words ~= zero shot prompting
Give examples of solving task ~= few shot prompting
Allow person to practice task ~= finetuning
The methods of specializing LLMs can be categorized according to the level of access to a model: black box (least visibility, lowest effort), grey box, and white box (highest visibility, highest effort).
black box - you are restricted to interact only with the model's API, think ChatGPT. In this setup, your knowledge is confined solely to the outputs produced by the model, with no visibility into its internal mechanisms.
grey box - partial information. For example, when dealing with the GPT-3 API, you might be privy to details such as token generation probabilities. This information serves as a valuable compass, you can formulate and refine appropriate prompts that can extract domain-specific knowledge from the model.
white box - the most comprehensive level of access. Here, you enjoy complete authorization to the Language Model (LLM), its parameter configuration, training data, and architectural design.
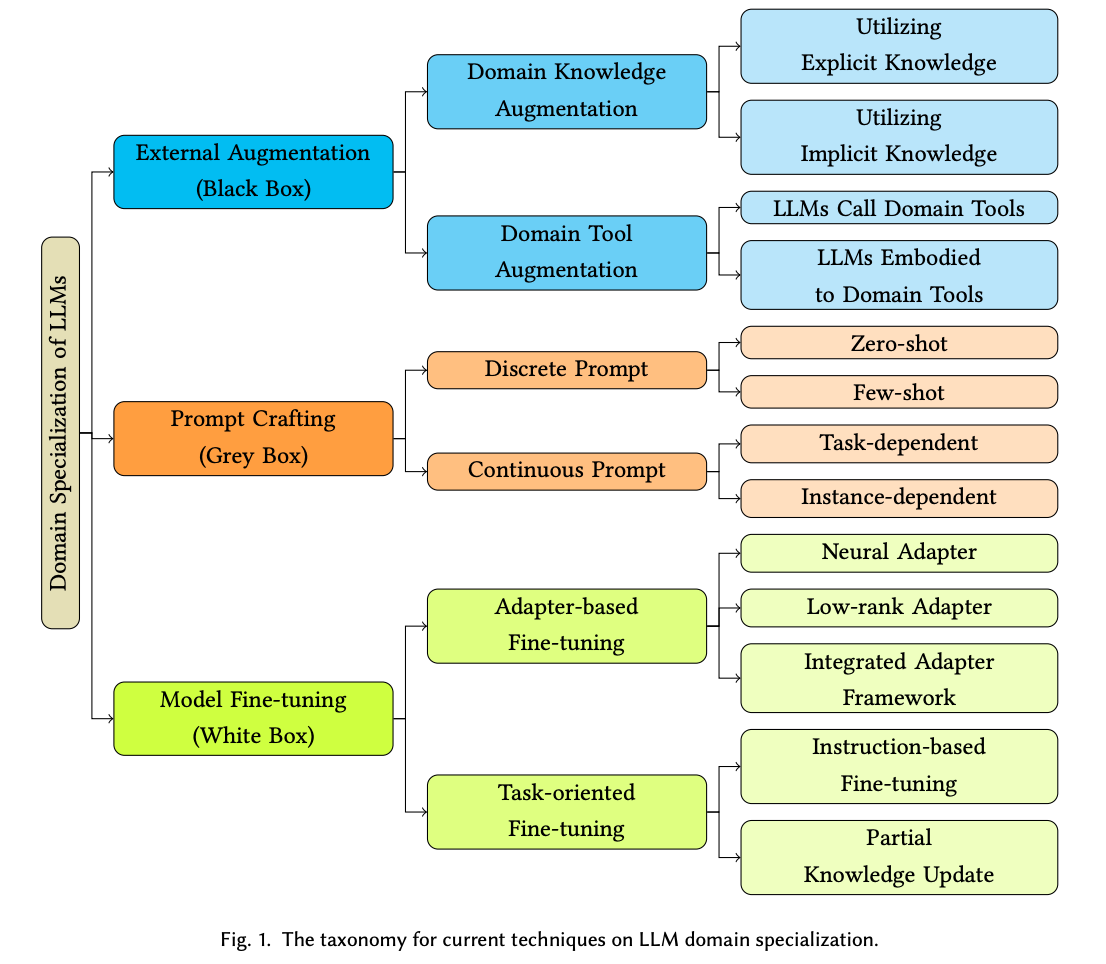
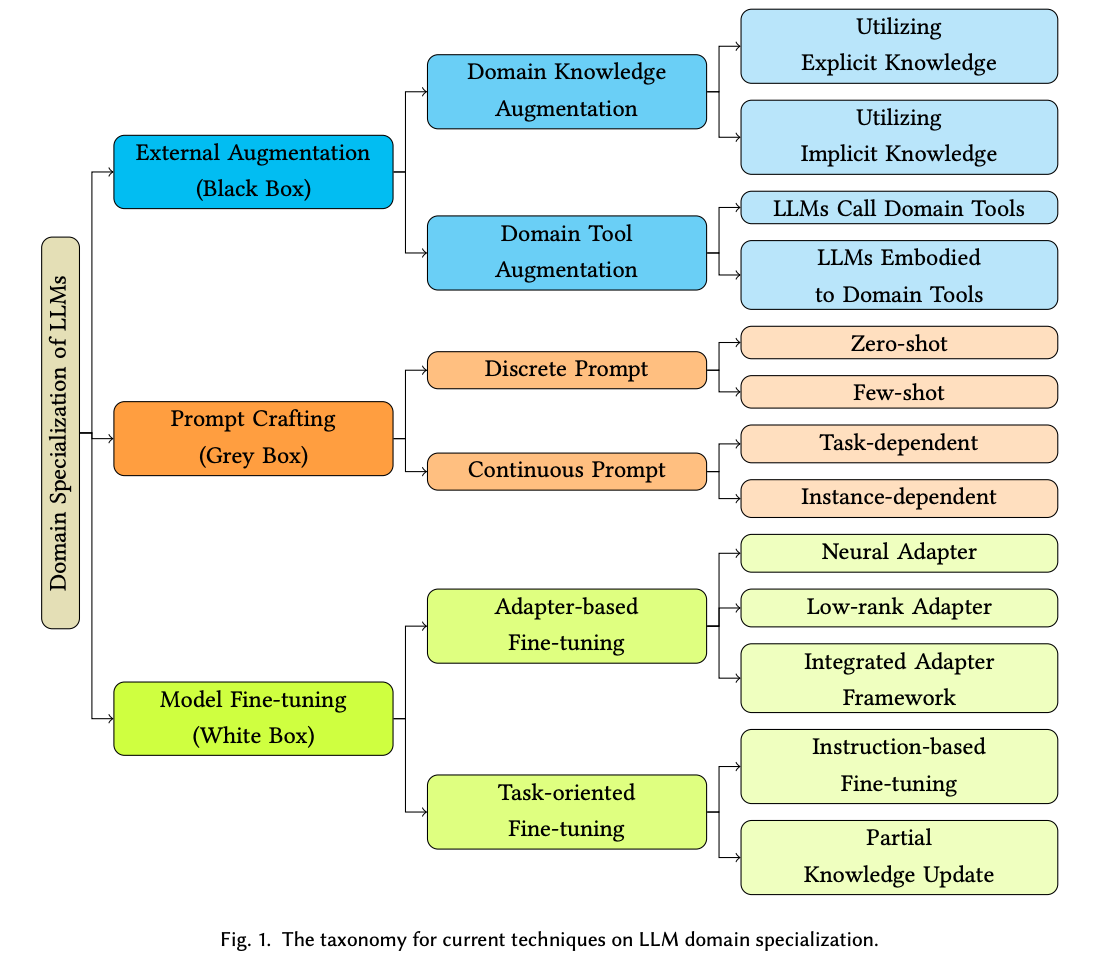
Source: Domain Specialization as the Key to Make Large Language Models Disruptive
In essence, these three assumptions delineate the varying degrees of access we may hold to a model, spanning from limited external interaction to possessing intricate insight into the model's underlying mechanisms. Which one should you use? It depends!
You can get a pretty good start if you just focus on prompt engineering. In fact, many startups today use prompting as a way to quickly get value to raise a first round of funding. For me personally, as an early stage investor that can be a detractor. I agree with Karpathy “I also expect that reaching top tier performance will include finetuning, especially in applications with concrete well-defined tasks where it is possible to collect a lot of data and "practice" on it”.
For big models, zero shot and few shot work, while for small models, you get more wins from fine-tuning.
Fine-tuning
Fine tuning is the most complex way to specialize an LLM. You can get some wins by supervised fine-tuning and then the hardest part might be RLHF (optimizing a language model with human feedback) , which brought us ChatGPT. Karpathy was strongly advising to not do RLHF at the State of GPT, mostly OpenAI got it in production. It took Google quite a while to RLHF its models, they already had big models but maybe not safe models. Llama2 from Meta also started to use RLHF, the graph is before LLama2.
Direct preference optimization from Stanford has been recommend. Instead of reinforcement learning you use supervised learning https://arxiv.org/abs/2305.18290 - because reinforcement learning is brittle and you need hyperparameter tunning and it’s hard to get it working.
Does fine tuning actually help with new task behavior?
Kaggle grandmaster from H2O that if you don’t already have some capabilities in a big model, fine tuning won’t save you which was kind of a depressing news. Beacause it means just the big companies can play in LLMs. Although others disagree and say if you force the models you can add some capabilities in there.


One interesting piece of evidence in this direction is the GOAT paper. GPT4 can’t do arithmetics. If you have additions, subtractions of multiplications of multiple digits, GPT makes quite a few mistakes, but it seems you can fine tune some models to get them to multiply and add larger digits. With fine tuning you can instill some new capabilities that are not there in the models.
Classical finetuning approaches
Look at the images top down.

Source: Sebastian Raschka
Feature based approach: Historically there’s this feature based approach of fine tuning where you keep a common trunk and just use the last layer activations as an embedding (a representation of the input). It's called transfer learning and was used heavily with imagenet trained trunks. You could train a model on imagenet and then use that frozen model for new pictures and then get the activations in the last layer. And let’s say if you had your own pictures you wanted to classify, hot-dog or not hot-dog, you could use the final layer representation and build on top of that an SVM or linear layer classifier that based on your small restricted data set can guess if your picture has a hot-dog or doesn’t have a hot-dog. This was a good way to train things fast, with few parameters on small data sets and use all the representation power that comes from training a big convolutional network on imagenet.

Source: Hot-Dog or not hot-dog app fron Jian Yang on Sillicon Valley show
Fine-tuning I: instead of just using the last layer, you could actually freeze most of the trunk of the network and keep the last few layers, or add a few layers and fine tune them, change the parameter values for those few layers on your task
Fine tune II: update all the layers, you can get the best performance but it’s the most expensive because you have to back-propagate through the entire model, while the other models back-propagate just through a few parameters.
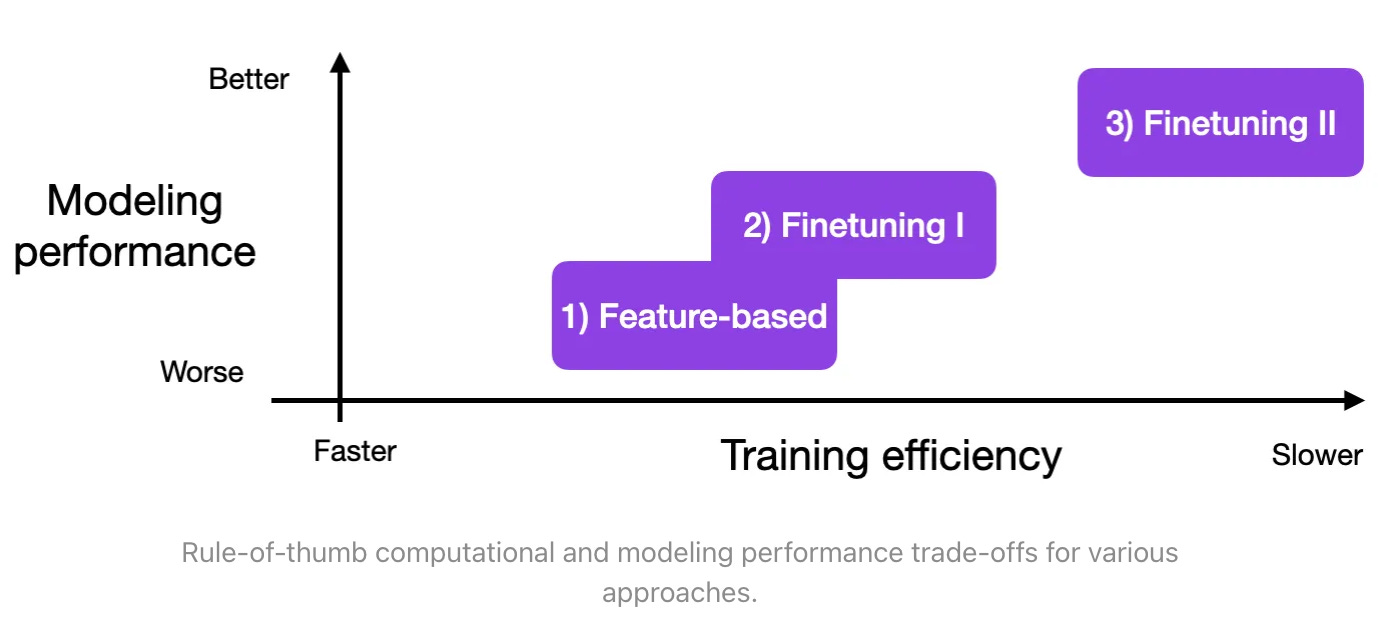
Source: Sebastian Raschka
LLM fine tuning
In LLMs you can think the same, you could use a BERT encoder and for the CLS token in the last layer of the BERT encoder you could put an NLP multilayer perceptron on top of that token and freeze the layers and just learn how to convert the CLS token to solve your classification task, let’s say it’s sentiment detection. Or you could backpropagate through a few layers of BERT, or you could propagate through the entire BERT or transformer model.

Source: https://arxiv.org/abs/1810.04805v2
Efficient Fine Tuning
This is the general setup and there are efficient methods of fine tuning, one of them is using adapters. Instead of training through the entire network, because it’s expensive, you could fine tune just the last layer. Or maybe you don’t want to fine tune just the last layer but you want more control over what you fine tune. So what people do is fine tuning with adapters. Maybe you want to fine tune some translation models or sentiment detection model in a separate language, you might add some parameters that are specific to a language. What they do is just insert between the standard layers of transformers some small layers that adapt the current task. So that’s one way to do fine tuning with efficient parameters.

Source: https://arxiv.org/abs/2101.00190
Another way is prefix fine tuning, where you fine tune end to end (top picture) but in the bottom picture you keep the transformer frozen and you just learn how to embed some inputs. You learn a few parameters that are the first few tokens in you input and then you concatenate them to the original input that you would use for your fine tuning task and the model learns somehow how to condition the output. You keep moving this prefix that is hard coded so that it modifies the output and it solves your final task. With 0.1% param and fine tuning the embeddings that you prepend to you input you can make the models adapt.
Prefix fine tuning is powerful because you don’t change the network at all, you just put some embeddings in there. But everyone now is using LoRA and qLoRA and it’s a third method that’s efficient and it’s much more beautiful than the two methods mentioned until now. All of them are pretty simple. Every one of these methods does only a bit of model surgery.
Side discussion about getting strong models using the high quality proprietary models as data source and finetuning open source models
Stanford Alpaca appeared after facebook launched Llama in March 2023, they got ChatGPT to generate 53k examples and then quickly fine tune Llama on top and say we can catch up to OpenAI by learning from the ChatGPT examples. Soon after the Alpaca release there was the famous “We have no moat” blogpost from a Google engineer. It seemed like open source models can get as good as Openai’s GPT or Google’s internal models. A few weeks later a team from Berkeley followed up with a the paper The False Promise of Imitating Proprietary LLMs which finds that Alpaca and similar approaches mostly imitate the style of ChatGPT and if you’d look into factuality, if the answers were correct, they would be bad compared to ChatGPT.
ORCA from Microsoft Research, gets data from GPT4 but the examples are more detailed with step by step instructions and if you make an effort to generate much better data you can get closer to replicating the main model. Just extracting data out of the model naively seems to copy style but if one spends a lot more effort you can actually get some quality improvements.
Fine-Tuning with Low-Rank Adaptation of Large Language Models (LoRA)

Image: Parameter-efficient fine-tuning methods taxonomy - good paper
The basic idea, you have a network that’s already trained and you want to train it on a new task. You update all the parameters, however it turns out it’s quite expensive if you have 65B parameters that you need to change every time, that’s 150GB, it’s a lot of memory access which takes energy and your GPUs heating up.
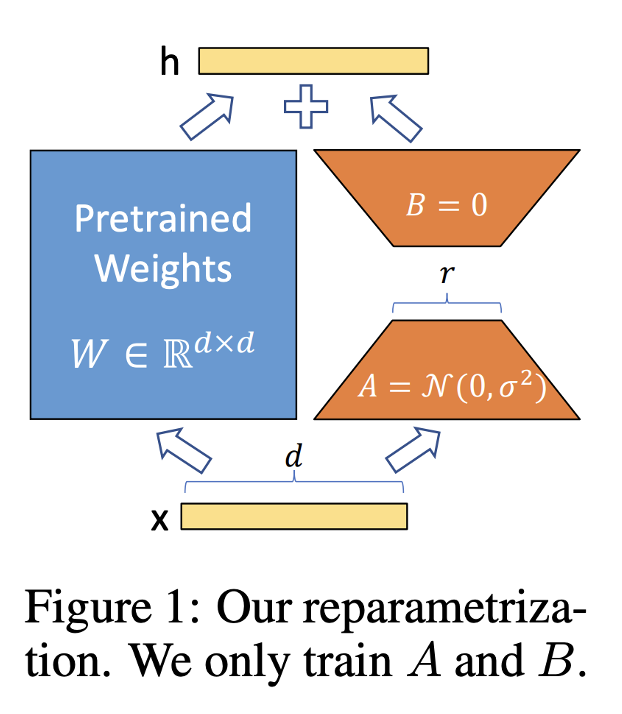
Source: LoRA paper
Instead you might insert some extra layers between the layers, that’s the adapter idea. You insert some smaller layers in between and train their parameters. Or you could just add a side matrix. LoRA allows you to significantly reduce the number of trainable parameters, you can often perform this method of parameter efficient fine-tuning with a single GPU and avoid the need for a distributed cluster of GPUs. Since the rank-decomposition matrices are small, you can fine-tune a different set for each task and then switch them out at inference time by updating the weights.
Lora is able to get the same accuracy as end to end fine tuning but is much cheaper in training since you update a small set of parameters.
In practice, HuggingFace knows what was the original model and knows how to merge. At inference time to make it fast, you can multiply the A and B matrix and get a bigger matrix that you know it’s low rank and just add it to the W matrix and that makes it so that you compute just the modified W matrix at inference. Model management is much easier because you fine tune on multiple tasks and you can swap in and out tasks. So it’s a very light weight way to adapt a big model to lots of tasks. To give a hypothetical example, you can adapt it to do sentiment detection or summarization on legal data or do talking in a dialect, you can fine tune all of these and basically you just have a few matrices on the side and you have a megabytes not gigabytes this way and at serving time you can decide ok I’m switching to this task, let me add this matrix and you can do it pretty fast in feed forward, so you could serve multiple models with the same machine, with the same space. This is a downside of lora also if you want to run several tasks in the same batch. In the same batch it won’t work.
This was fine tuning in review. The article explores and elaborates on a recent talk Yaroslav Bulatov and Cosmin Negruseri presented in the deep learning SF meetup. Thanks to Yaroslav and Cosmin for giving the talk and reading drafts of my blog.
If you enjoyed it please leave a comment and share. For questions or suggestions about the next blogpost, feel free to email me at oe.olteanu@gmail.com
Papers mentioned
Domain Specialization as the Key to Make Large Language Models Disruptive
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Really great writing and useful for information to study