

Agentic systems: panning for gold


In the rush to harness AI's potential, it’s essential to distinguish between groundbreaking innovations and overhyped promises. While fully autonomous AI agents, Level 5, are a distant reality, significant value can already be realized with current Level 3 agentic systems. This post explores how businesses can leverage these systems effectively, avoid common pitfalls, and prepare for future advancements.
Current Capabilities and Limitations
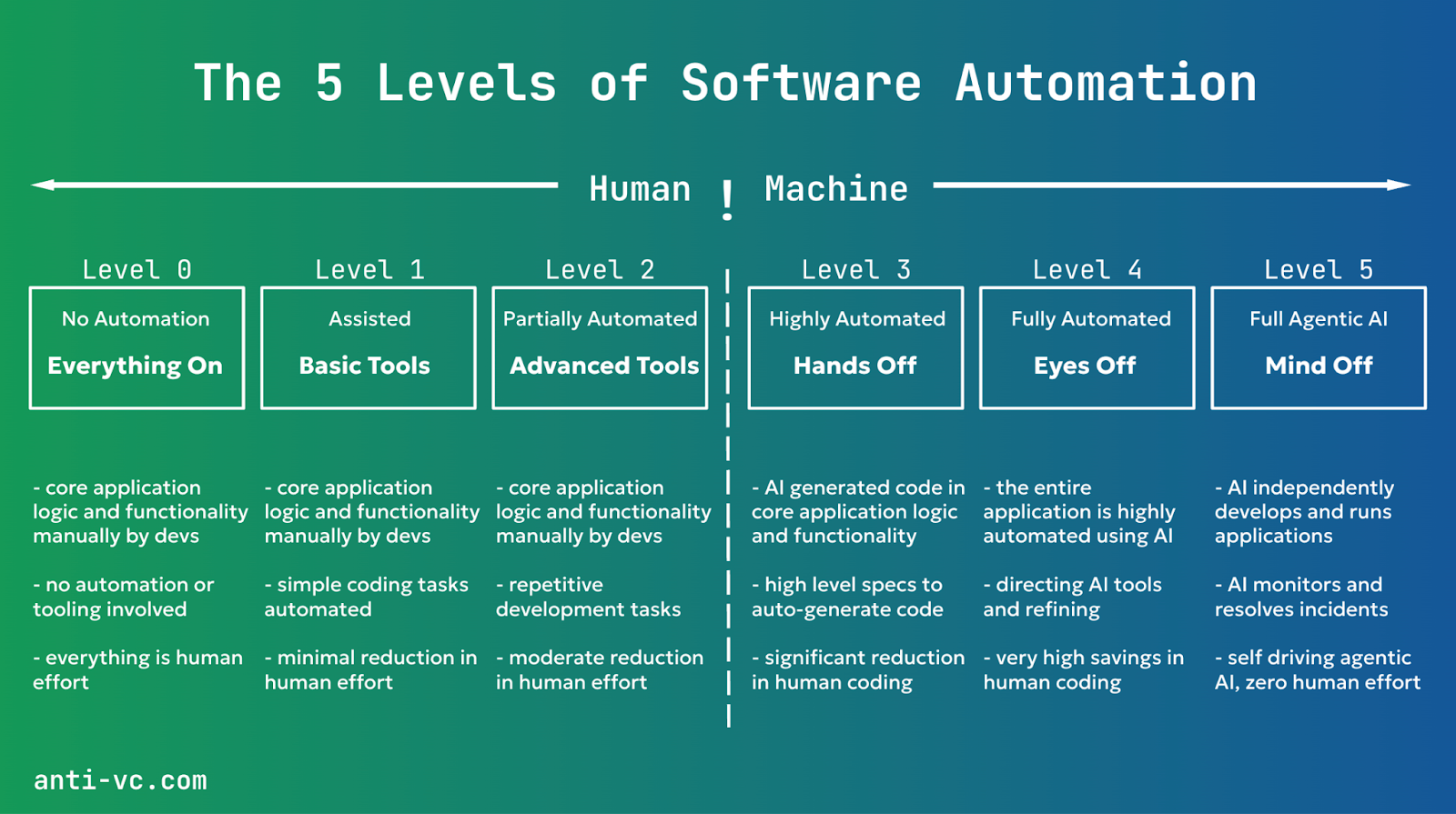
One can think of agentic system automation as similar to the five levels of automation of self-driving cars. Today, most agentic systems are Level 3, like summarizing a call and searching legal documents for specific use cases, but truly autonomous agents, Level 5, are a long way off. The primary barrier to reaching Level 5 autonomy is training. It could take a decade to address long-tail failures, highlighting the necessity of realistic expectations and incremental advancements. There are no magic shortcuts.
Understanding vs. Reasoning
Current AI models excel at understanding through rich ontologies (e.g. that water is wet, things fall down, a son has a mother, etc), but lack true reasoning capabilities. Reasoning implies a self-reflective capacity. Larger models have a deeper/more sophisticated ontology, which they can then use to understand the prompt, not in terms of its text, but the abstract concepts described therein, which map to items in its ontology. The model can guess the likely next item in the output sequence from this understanding.
One aspect of understanding that I find quite interesting is the notion of modality invariance, i.e. that a certain abstract concept that a model has learned from reading oodles of text can quickly be learned from a modest set of examples in an alternate modality. For example, if you show a pre-trained model a set of labeled images, it associates those images with the abstract concepts represented by the text, and this modality invariance then lets it recognize novel, unlabeled images. The same can be done for other modalities, e.g. audio or other sensory data. Fixie does this. One of the coolest things that I've seen is when the model recognizes some concept it only read about in speech that's given to it at inference time, e.g., "it sounds dangerous where you are, be careful!" Again, this isn't "reasoning," in my opinion, but cross-modal invariance is still pretty magical.
Larger models are better at this invariance because of their richer ontologies. This suggests a future in which large, expensive models are augmented by an array of smaller, cheaper, pluggable projections (possibly distributed) that give the central model various new "senses."
Optimized Models for Better Performance
If you want great performance on open-domain inputs, bigger is almost always better for the abovementioned ontological reasons. One caveat is that you can't think forever in a multi-agent (or agent-human) setting! Humans tend to respond to conversational inputs, at least with an "um" (which itself is a signal that more computation is required!), in < 500 ms. So, smaller fine-tuned models can hold their own and outperform a larger model for conversations and other real-time interactions. This difference is even more pronounced when you consider the cost and speed. Smaller LLMs, such as Llama3, are roughly 100x cheaper and 10x faster than larger models such as GPT4. The challenge is that sometimes a difficult prompt might come along, which the smaller model struggles with. This is where dynamic routing can provide a lot of value, where only the "hard" prompts go to the larger models, and the "easy" prompts go to the faster, cheaper models to balance LLM performance with overall UX. Unify is building a dynamic router to address this problem. I am continually looking for new model-serving techniques that provide both speed and deep understanding! Please DM/email me.
Building Reliable Systems
As agentic systems become more common, the search space becomes ever more complex. Every single intermediate prompt, intermediate LLM, and a small tweak to the "flow" can have a drastic impact on the final system performance. With such a complex, high-dimensional, non-differentiable search space, an obvious question arises: can we automate this process, where the system automatically learns to select the correct prompts and the correct models in all intermediate steps of the system? This is similar to how a neural network "learns" to select the network weights, driven by a higher-level task the network is trained on. This is what tools like DSPy and Unify are working towards so that app builders don't need to spend hours tuning each system prompt and LLM choice, they can define the general flow and then configure the agentic system to optimize itself.

Evaluation Challenges
Last week, I spoke at the Gen AI summit, and my view on evaluation was most controversial, given that some of the other panelists invested in this market. IMHO, many teams don't want to admit it, but for many use cases, human evaluation is the only way to get a reliable signal. Either that or fall back on low-fidelity metrics (often using other LLMs) with large error bars that are useless for fine-grained decisions. These two bad options keep many teams doing "vibes-based development" with small-scale smell testing and rudimentary metrics.
Some teams go to the other extreme and struggle with top LLMs being overly "safety-aligned." For example, if you’re making a mental health check-in chat app, LLMs that refuse to talk about touchy issues like addiction or self-harm are worse than useless. Since large models converge towards their testing datasets, the capabilities of the top LLMs today are comparable, and the big difference between them is in their safety alignment. Evaluating behaviors like refusal patterns: what questions will a given LLM refuse to engage with? is one of the concrete areas where you can capture a good signal using automated metrics to learn a lot about whether a given model is suitable for your use case.
I keep a list of 50+ newly minted LLM evaluation startups; my opinion is that this is not a market. The need for it is inversely proportional to model quality. Similar to how newer/larger/better models like GPT-4o require significantly less prompt engineering than leading models even a year ago, for many practical use cases, the need for rigorous evaluation is already evaporating as the models become "good enough." Nobody evaluates for evaluation's sake — it's always driven by business needs — and unless a team gets burned by unexpected behavior, they're not going to invest heavily in evaluation. Mission-critical systems invest in data, model, and deployment quality, they test and evaluate the entire application, not just the model. One company offering tools for testing at scale is Kolena. The audience at the Gen AI summit was mostly interested in Agentic Quality.

Potential of Retrieval-Augmented Generation (RAG)
RAG is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. Agentic retrieval frameworks have become very popular recently, with an increasing focus on tool use and agentic hierarchies rather than simple similarity searches with respect to the input prompt. As with any agentic system, the main challenge is building a reliable system where each intermediate step in the flow consistently behaves as expected. Having robust telemetry is important here, but so are tools that can automate the finer details driven by the task, removing manual effort from the LLM engineer.
One useful company for this problem is Superlinked. They focus purely on retrieval - but on more realistic data, not just strings vectorized with an LLM. Let's say you have an application table with 10 columns, with Superlinked you can generate a vector per row, composed of vectors of all the columns, using models appropriate to each column type. And then at query time, you can run queries like "give me rows relevant for query X, which also skew recent and popular." Here is an in-depth comparison for those who don’t know what VectorDB to pick.
Embracing Intermediate Levels
Some believe that fully autonomous systems, Level 5, are necessary for significant AI value. While Level 5 systems are an ultimate goal, Level 3 systems already provide substantial value. For instance in customer support and legal domains, these systems automate repetitive tasks and enhance efficiency without needing full autonomy.
Sarah Tavel gives as an example EvenUp. EvenUp sells the demand package for personal injury lawyers vs an AI tool to help the lawyers create better demand packages. Essentially the demand package is “a summary of the case, the medical costs of the injury (including lost wages), and then a recommendation on the settlement value from the defendant’s insurance company. Law firms have stretched lawyers, paralegals, or outsourced groups writing these documents”. EvenUp picked a function/domain where we can have agentic systems in small quantities, and the AI does not have to be truly autonomous to generate value.
What is essential here is the lack of/light system of records. In addition to a weaker incumbent system of records, EvenUp built the biggest proprietary data set in the industry. The users are directly incentivized economically, with more revenues vs cost cutting.

Games could be another suitable function to sell the work vs. the software. One doesn’t need to hire writers to create long-term scenarios; there could be infinite storylines that adjust to the player. And because it’s a game, when the agent occasionally fails and gives the wrong results, it’s not the end of the world.
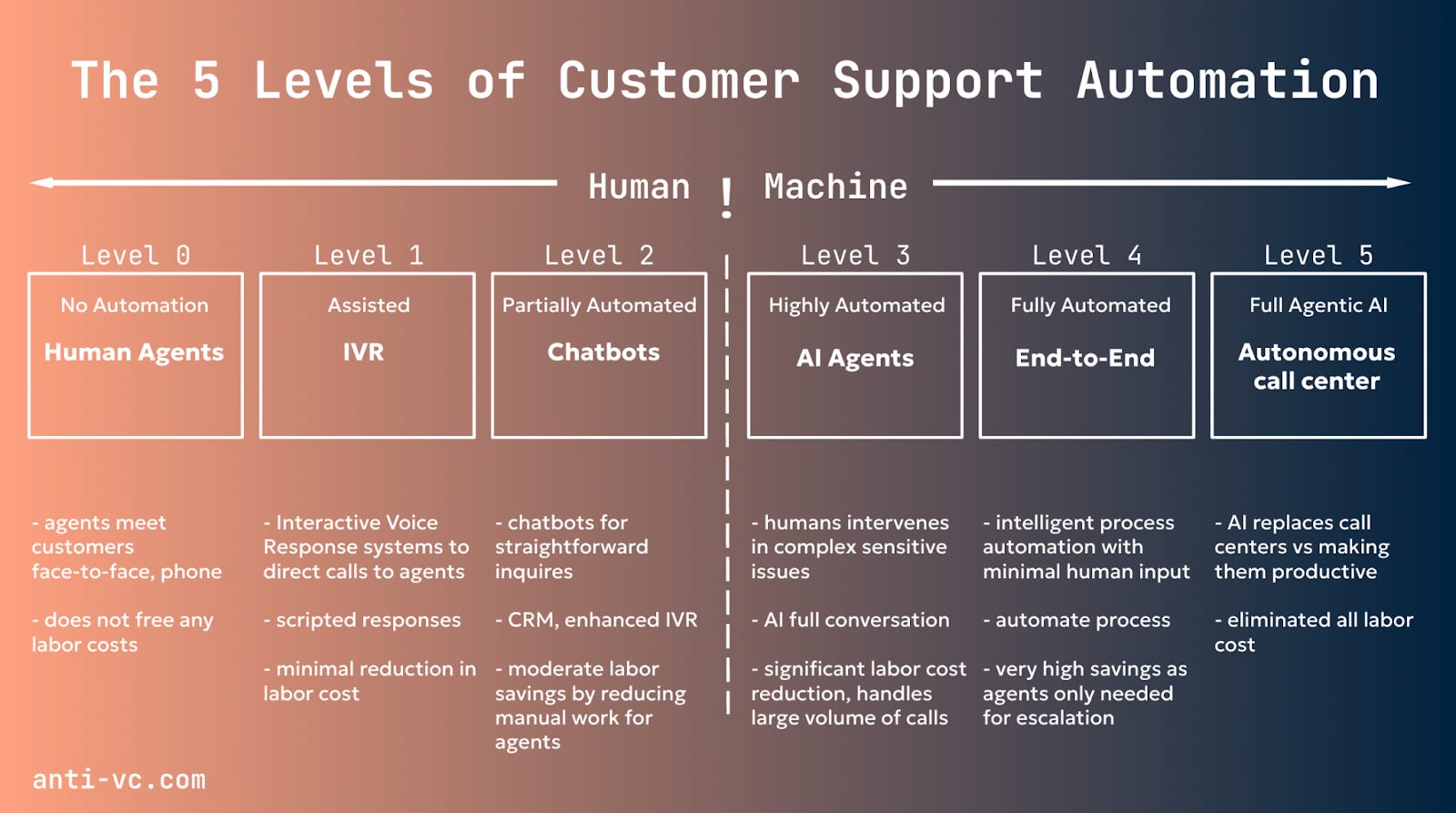
Customer Support Automation
One example of an application where customers can easily justify the Return on Investment (ROI) is Customer Support. Customer support involves many repetitive tasks, knowledge retrieval, and dealing with originally happy customers who turned unhappy due to being handed off between departments - it’s not a pleasant experience. People work long hours, there is a high attrition rate. So, AI can be really helpful in customer support. First, AI can act like a human and improve the customer experience. And second, when there is a large amount of siloed information, AI can help you connect the dots.
AI will be cheaper, faster, and more accessible. AI will be like electricity, the difference will be, can you build the best product that delights customers? Can you build an ecosystem where customers will generate value for each other? AI is only as good as data. AI will be a piece of infrastructure that everyone will use, like having an additional database, but won’t differentiate your product in the long term. It’s not only the data and the model, it’s the quality of the infrastructure and what pieces of the product it affects - “When you design a UI, can you design a workflow in a way that makes you more efficient and effective? You have to look at the system as a whole and say I can't think of a better system “ - Tim, CTO of Cresta AI, on a panel I moderated last week for the Gen AI summit.
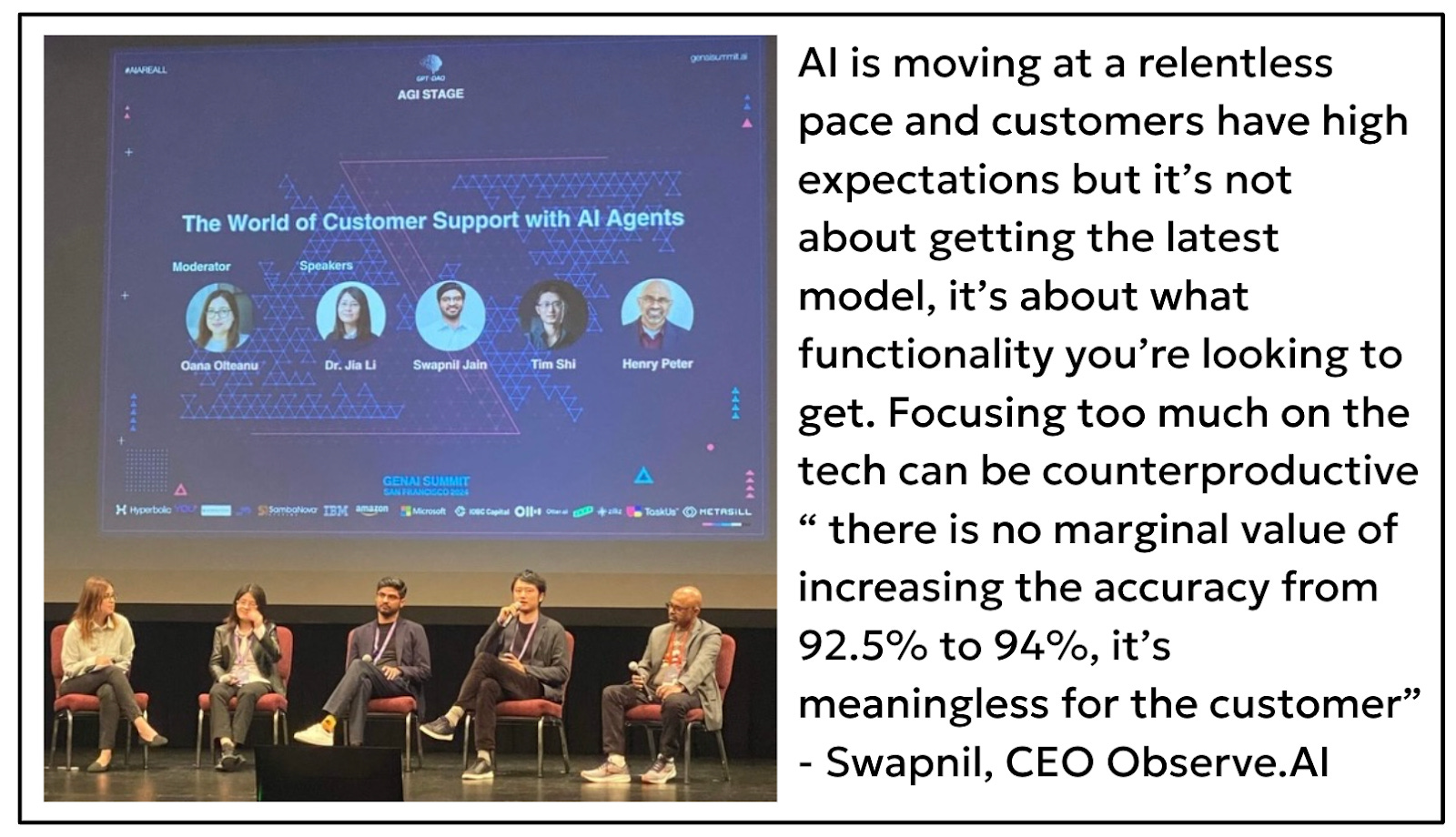
Nowadays, there are a lot of models, and everybody competes on the model size and the open source benchmarks. If everybody is learning from the internet data, you can easily run into an overfitting problem. So, for companies building applications or solving specific problems, it's best to build your target, build your metrics, and always evaluate your model, approach, and things with the metrics you care about. So, in customer support, you won’t chase the largest best model, you will care about different factors like latency, accuracy, and tone. People can get distracted and pay too much attention to the latest models and benchmarks and pay less attention to the problem they are solving and the data that represents the problem they are solving, which is not a math problem, it’s a customer problem with its own evaluation and metrics around it.
“Evaluation frameworks and metrics are different from one use case to another. If you want to generate a report, you care less about how long it takes, you care about the accuracy. But if you have a conversational agent for a patient, you want it to be empathetic. I encourage companies to come up with their own metrics and evaluation frameworks” - Dr. Jia Li
A good framework of what could be automated vs. not is customers' tolerance level on error rates. What’s the cost of the error? And when it’s high, you don’t want to put automation there. We are trying to replace the copilots with AI, but it works as long as humans watch them. Like airplane pilots, flights could be on autopilot, but we still have pilots sitting in and supervising. Support has been regarded as a cost for businesses, and in the future, it will be a way to differentiate, it’s an advantage to have happy customers, and the lines between product and support will get blurred.
Current Level 3 agentic AI systems offer substantial value by automating specific tasks, optimizing performance with dynamic routing, and enhancing reliability through robust design and evaluation. Businesses should focus on practical applications of Level 3 systems, leverage existing tools for optimization, and stay informed about emerging AI trends to remain competitive and prepare for future advancements. Please reach out if you’re working on the infrastructure for agentic systems (e.g. training) or their application. Same if you are interested to discuss more in depth any of the points in this blogpost. Thank you!
I am intrigued by this idea "human evaluation is the only way to get a reliable signal"
Do you mean RLHF or something more? For example, Alan Cowen from Hume AI believes RLHF will always be biased and instead need to move to something more akin to evaluation based on how models actually affect users (eg, https://x.com/AlanCowen/status/1613293979071664146)